
Studying Databricks ML Professional With Me - Using Spark ML Effectively on Databricks
A Practical Guide for ML Engineers and Databricks ML Professional Candidates
1. Introduction
Apache Spark ML (commonly referred to as SparkML or MLlib) is designed to build scalable, distributed machine learning pipelines on large datasets.
In the Databricks Certified Machine Learning Professional exam, SparkML is not tested as a library in isolation. Instead, candidates are expected to understand:
- When SparkML is the right choice
- How to construct end-to-end ML pipelines
- How to train, tune, evaluate, and deploy models
- How to choose between SparkML and single-node models for inference
This tutorial provides a practical, exam-aligned guide to using SparkML effectively in real-world Databricks workflows.
2. When Should You Use SparkML?
Choosing SparkML is fundamentally a data, model, and inference-type decision.
2.1 Data Characteristics
SparkML is recommended when:
- Your data already lives in Delta Lake / Parquet and is loaded as a Spark DataFrame
- The dataset is too large for a single machine
- Feature engineering requires distributed processing
- You want training and inference to share exactly the same logic
SparkML is not ideal when:
- The dataset fits comfortably in memory on a single node
- You require advanced algorithms not available in SparkML (e.g., XGBoost, deep learning)
2.2 Model Types Supported by SparkML
SparkML is strongest for classical machine learning:
- Classification:
LogisticRegression,RandomForestClassifier,GBTClassifier - Regression:
LinearRegression,RandomForestRegressor,GBTRegressor - Recommendation:
ALS - Clustering:
KMeans
SparkML is not designed for deep learning workloads such as CNNs or Transformers.
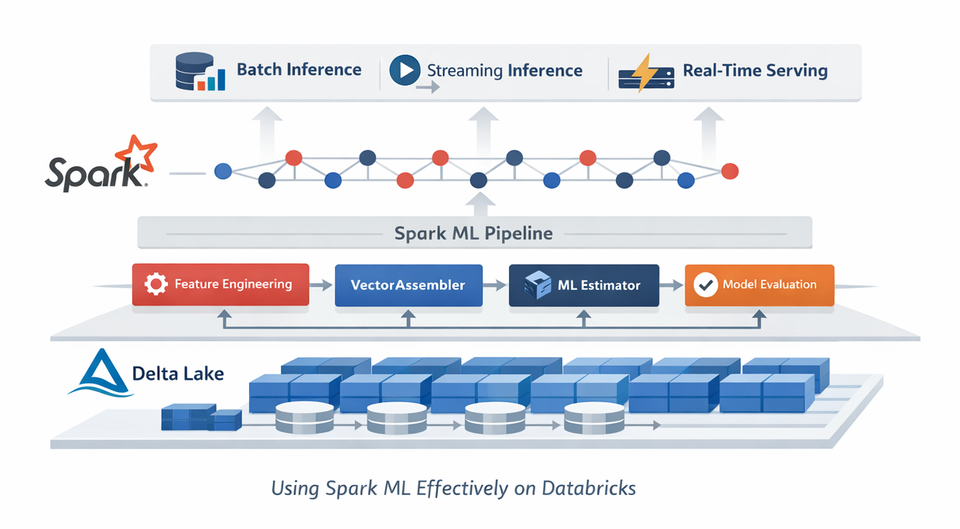
2.3 Use Case: Batch, Streaming, or Real-Time?
| Use Case | Recommended Approach |
|---|---|
| Batch inference (daily/hourly scoring) | SparkML |
| Streaming inference (structured streaming) | SparkML |
| Real-time / low-latency inference | Single-node model + Model Serving |
Key exam insight: SparkML excels in data-parallel batch and streaming inference.
Real-time APIs usually require single-node models.
3. Constructing an ML Pipeline with SparkML
SparkML is built around pipelines, which ensure consistency between training and inference.
3.1 Pipeline Components
A SparkML pipeline consists of:
- Transformers – data preprocessing
- Estimator – model training
- Pipeline – ordered sequence of stages
3.2 Common Transformers
| Task | Transformer |
|---|---|
| Handle missing values | Imputer |
| Encode categorical features | StringIndexer |
| One-hot encoding | OneHotEncoder |
| Feature scaling | StandardScaler |
| Feature vector assembly | VectorAssembler |
Exam tip: Always setStringIndexer(handleInvalid="keep")for production pipelines.
3.3 Example Pipeline
from pyspark.ml import Pipeline
from pyspark.ml.feature import (
StringIndexer, OneHotEncoder, VectorAssembler, Imputer
)
from pyspark.ml.classification import LogisticRegression
indexer = StringIndexer(
inputCol="category",
outputCol="category_idx",
handleInvalid="keep"
)
encoder = OneHotEncoder(
inputCol="category_idx",
outputCol="category_ohe"
)
imputer = Imputer(
inputCols=["num1", "num2"],
outputCols=["num1_imp", "num2_imp"]
)
assembler = VectorAssembler(
inputCols=["category_ohe", "num1_imp", "num2_imp"],
outputCol="features"
)
lr = LogisticRegression(labelCol="label")
pipeline = Pipeline(
stages=[indexer, encoder, imputer, assembler, lr]
)
model = pipeline.fit(train_df)
predictions = model.transform(test_df)
4. Choosing the Right Estimator
4.1 Classification
- Baseline:
LogisticRegression - Nonlinear patterns:
RandomForestClassifier,GBTClassifier
4.2 Regression
- Baseline:
LinearRegression - Nonlinear relationships:
GBTRegressor,RandomForestRegressor
4.3 Recommendation Systems
- Collaborative filtering:
ALS
5. Hyperparameter Tuning with SparkML
SparkML provides distributed hyperparameter tuning via:
CrossValidator(more robust, slower)TrainValidationSplit(faster, less compute)
5.1 Example: Cross-Validation
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
from pyspark.ml.evaluation import BinaryClassificationEvaluator
paramGrid = (
ParamGridBuilder()
.addGrid(lr.regParam, [0.0, 0.01, 0.1])
.addGrid(lr.elasticNetParam, [0.0, 0.5, 1.0])
.build()
)
evaluator = BinaryClassificationEvaluator(
labelCol="label",
metricName="areaUnderROC"
)
cv = CrossValidator(
estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3,
parallelism=4
)
cvModel = cv.fit(train_df)
Exam insight:
For very large datasets,TrainValidationSplitis often preferred.
6. Evaluating SparkML Models
6.1 Classification
BinaryClassificationEvaluator- Metrics:
areaUnderROC,areaUnderPR
- Metrics:
MulticlassClassificationEvaluator- Metrics:
accuracy,f1,weightedPrecision
- Metrics:
6.2 Regression
RegressionEvaluator- Metrics:
rmse,mae,r2
- Metrics:
6.3 Clustering
ClusteringEvaluator- Metric:
silhouette
- Metric:
7. Scoring SparkML Models
7.1 Batch Scoring
scored_df = model.transform(batch_df)
scored_df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("batch_scores")
This is the most common SparkML inference pattern.
7.2 Streaming Scoring (Recommended Pattern)
The preferred Databricks approach uses foreachBatch.
def score_batch(microbatch_df, batch_id):
scored = model.transform(microbatch_df)
scored.write.format("delta") \
.mode("append") \
.saveAsTable("stream_scores")
stream_df = spark.readStream.table("incoming_stream")
query = (
stream_df.writeStream
.foreachBatch(score_batch)
.option("checkpointLocation", "/delta/chk/stream_scores")
.start()
)
Exam insight:foreachBatchis favored for reliability and operational control.
8. SparkML vs Single-Node Models for Inference
8.1 When to Use SparkML
- Large-scale batch scoring
- Streaming inference
- Distributed feature engineering
8.2 When to Use Single-Node Models
- Real-time, low-latency APIs
- Complex models (XGBoost, deep learning)
- Deployment via MLflow Model Serving
| Inference Type | Recommended |
|---|---|
| Batch | SparkML |
| Streaming | SparkML |
| Real-time | Single-node + Serving |
9. Key Takeaways (Exam Cheat Sheet)
- SparkML is ideal for large-scale, distributed ML
- Use Pipelines to ensure training–inference consistency
- Always handle unseen categories in production
- Choose evaluators based on task type
- Use SparkML for batch and streaming inference
- Prefer single-node models for real-time APIs
10. Final Thoughts
SparkML remains a core production tool in Databricks-centric ML systems, especially when data volume, reliability, and consistency matter more than raw model complexity.
For the Databricks Certified Machine Learning Professional exam, mastering SparkML is less about memorizing APIs and more about making the right architectural decisions.