
Studying Databricks ML Professional With Me - Overview
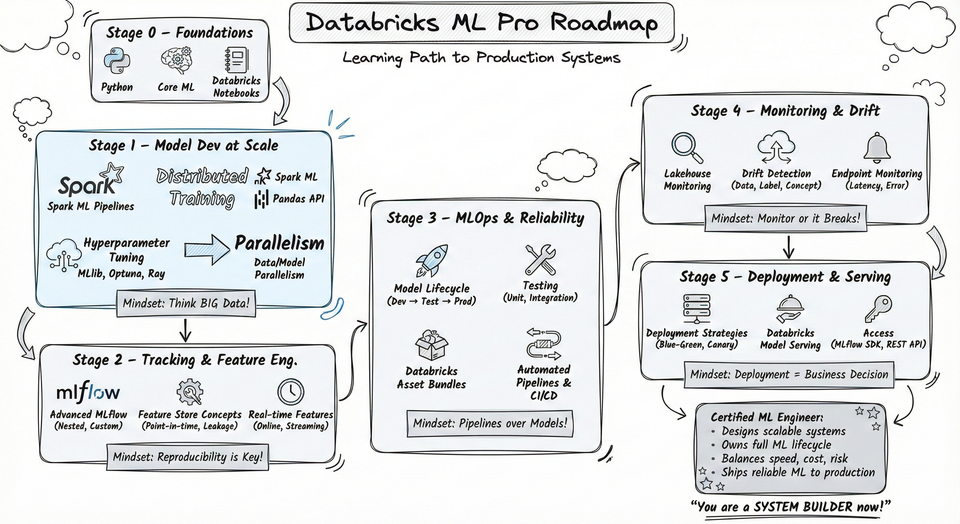
From Exam Blueprint to Production-Grade Machine Learning Engineering
Machine learning today is no longer about training a model in a notebook and celebrating a good accuracy score.
In real-world systems, machine learning is about scale, reliability, monitoring, deployment, and long-term maintenance. It is about building systems that survive messy data, changing distributions, growing traffic, and evolving business requirements.
This is exactly what the Databricks Certified Machine Learning Professional exam is designed to assess.
In this blog series — Studying Databricks ML Professional With Me — I will systematically walk through every exam objective, turning the official exam blueprint into practical, production-oriented learning material for modern machine learning engineers.
What Does “ML Professional” Really Mean?
The word Professional in this certification is not a formality.
The exam does not test whether you know machine learning algorithms in theory.
It tests whether you can design, implement, operate, and evolve machine learning systems at enterprise scale using the Databricks platform.
An ML Professional is expected to:
- Choose the right tools and frameworks for large-scale ML workloads
- Build end-to-end pipelines, not isolated models
- Apply MLOps best practices across development, testing, deployment, and monitoring
- Detect and respond to data drift, concept drift, and performance degradation
- Safely deploy models into high-traffic, business-critical environments
In other words:
This exam evaluates whether you can take responsibility for ML systems after the model is trained.
The Core Skill Areas of the Exam
The exam blueprint is structured into three major sections. Together, they form a complete lifecycle view of machine learning in production.
1. Model Development (Beyond Model Training)
This section focuses on scalable model development, not algorithm theory.
Key skills include:
- Knowing when and why to use Spark ML instead of single-node libraries
- Building Spark ML pipelines with proper transformers and estimators
- Scaling training and inference using:
- Spark ML
- Pandas Function APIs
- Ray
- Performing distributed hyperparameter tuning with tools like Optuna
- Using advanced MLflow patterns, including nested runs and custom model logging
- Designing feature pipelines with Feature Store, ensuring point-in-time correctness
The emphasis is always on engineering decisions, not syntax memorization.
2. MLOps (Where Most Candidates Struggle)
This is the heart of the Professional exam.
You are expected to understand machine learning as a system, including:
- Model lifecycle management and environment transitions
- Unit tests vs. integration tests for ML pipelines
- Automated retraining strategies triggered by drift or performance degradation
- Monitoring with Lakehouse Monitoring:
- Data drift
- Label drift
- Model performance trends
- Endpoint health (latency, errors, resource usage)
Many questions in this section ask:
What breaks if we change this?
Which test must be rerun?
Which metric matters most in production?
This is real ML engineering, not academic ML.
3. Model Deployment (Safe and Scalable Production Systems)
The final section focuses on serving and rollout strategies, including:
- Blue-green and canary deployments
- Traffic splitting and risk mitigation
- Custom model serving using MLflow PyFunc
- Querying models via SDKs and REST APIs
- Managing models, endpoints, and experiments using Databricks Asset Bundles
The key question is never “Can you deploy a model?”
It is always “Can you deploy it safely, monitor it, and roll it back if needed?”
How This Series Is Structured
In this series, I will follow the exam blueprint point by point.
Each blog post will focus on one specific exam objective, such as:
- “When should Spark ML be used?”
- “How should nested MLflow runs be structured?”
- “Which statistical test should be used for drift detection?”
- “How do you select the best model during automated retraining?”
For each topic, I will cover:
- The exam perspective (what the exam expects)
- The engineering rationale (why this matters in production)
- Common exam traps and misconceptions
- Practical decision frameworks you can reuse in real projects
This approach ensures that the content is:
- Exam-aligned
- Production-relevant
- Reusable beyond certification
How to Prepare for the ML Professional Exam (Strategically)
If you are preparing for this exam, here is the most important advice:
Do not study it like a traditional ML exam.
Instead:
- Think in systems, not models
Always ask: Where does this fit in the pipeline? - Focus on trade-offs and decisions
The exam rewards choosing the right approach, not knowing every option. - Understand Databricks-native patterns
Many correct answers align with best practices on the Databricks platform — even if alternatives exist elsewhere. - Practice reasoning, not memorization
Most questions are scenario-based and constraint-driven.
Why “Studying Databricks ML Professional With Me”?
This series is not a polished course and not a dump of exam answers.
It is a transparent, structured learning journey, where I:
- Use the official exam blueprint as a backbone
- Connect exam objectives to real ML engineering practice
- Share reasoning frameworks that apply far beyond the exam
If you are:
- Preparing for the Databricks ML Professional exam
- Transitioning from data science to ML engineering
- Building production ML systems at scale
Then this series is for you.
What’s Next?
In the next post, I’ll start with the first core topic:
When Should You Use Spark ML? — An Exam-Grade and Production Perspective
Stay tuned — and feel free to study with me.