
Demo 01: From Landing Files to Iceberg and Delta Tables on MinIO (Using Trino)
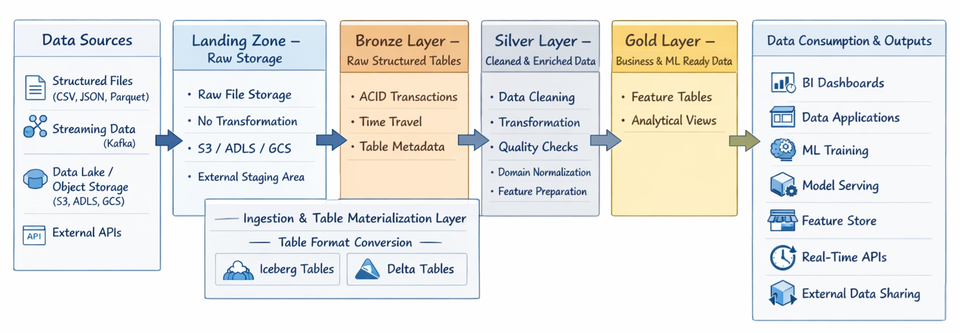
Parquet is a file format, while Delta and Iceberg are table formats that add transactional metadata layers on top of Parquet to provide ACID guarantees, schema evolution, time travel, and reliable data engineering workflows.
In this demonstration, we will implement a classic Lakehouse promotion pipeline:
Landing (raw parquet files on MinIO)
→ Bronze (Iceberg table)
→ Bronze (Delta table)
We will use:
- MinIO as object storage
- Trino as the query engine
- Hive connector to read raw parquet files
- Iceberg connector to create managed Iceberg tables
- Delta Lake connector to create managed Delta tables
This setup mirrors a Databricks-style Lakehouse architecture — but fully self-hosted.
1️⃣ Architecture Overview
Assume the following:
- MinIO bucket:
demo - Raw files already uploaded to:
s3a://demo/landing/nyc_taxi/2026/02/26/*.parquet
Your Trino catalogs:
| Catalog | Connector | Purpose |
|---|---|---|
| hive | hive | Read external parquet files |
| iceberg | iceberg | Managed Iceberg tables |
| delta | delta_lake | Managed Delta tables |
We will:
- Register landing parquet files via Hive connector
- Promote them to an Iceberg Bronze table
- Promote them to a Delta Bronze table
2️⃣ Step 1 — Register Landing Parquet Files (Hive External Table)
This does not move or modify data.
It only tells Trino how to read the files.
CREATE SCHEMA IF NOT EXISTS hive.landing;
DROP TABLE IF EXISTS hive.landing.fhvhv_tripdata_202601_landing;
CREATE TABLE hive.landing.fhvhv_tripdata_202601_landing (
hvfhs_license_num VARCHAR,
dispatching_base_num VARCHAR,
originating_base_num VARCHAR,
request_datetime TIMESTAMP(6),
on_scene_datetime TIMESTAMP(6),
pickup_datetime TIMESTAMP(6),
dropoff_datetime TIMESTAMP(6),
PULocationID INTEGER,
DOLocationID INTEGER,
trip_miles DOUBLE,
trip_time BIGINT,
base_passenger_fare DOUBLE,
tolls DOUBLE,
bcf DOUBLE,
sales_tax DOUBLE,
congestion_surcharge DOUBLE,
airport_fee DOUBLE,
tips DOUBLE,
driver_pay DOUBLE,
shared_request_flag VARCHAR,
shared_match_flag VARCHAR,
access_a_ride_flag VARCHAR,
wav_request_flag VARCHAR,
wav_match_flag VARCHAR,
cbd_congestion_fee DOUBLE
)
WITH (
format = 'PARQUET',
external_location = 's3a://demo/landing/nyc_taxi/2026/02/26/'
);
What happens in MinIO?
Nothing new is created.
Trino simply reads the existing parquet files.
3️⃣ Step 2 — Create Iceberg Bronze Table
Now we create a managed Iceberg table.
CREATE SCHEMA IF NOT EXISTS iceberg.bronze;
DROP TABLE IF EXISTS iceberg.bronze.fhvhv_tripdata_raw;
CREATE TABLE iceberg.bronze.fhvhv_tripdata_raw (
hvfhs_license_num VARCHAR,
dispatching_base_num VARCHAR,
originating_base_num VARCHAR,
request_datetime TIMESTAMP(6),
on_scene_datetime TIMESTAMP(6),
pickup_datetime TIMESTAMP(6),
dropoff_datetime TIMESTAMP(6),
PULocationID INTEGER,
DOLocationID INTEGER,
trip_miles DOUBLE,
trip_time BIGINT,
base_passenger_fare DOUBLE,
tolls DOUBLE,
bcf DOUBLE,
sales_tax DOUBLE,
congestion_surcharge DOUBLE,
airport_fee DOUBLE,
tips DOUBLE,
driver_pay DOUBLE,
cbd_congestion_fee DOUBLE,
shared_request_flag VARCHAR,
shared_match_flag VARCHAR,
access_a_ride_flag VARCHAR,
wav_request_flag VARCHAR,
wav_match_flag VARCHAR,
_ingest_timestamp TIMESTAMP(6),
_source_prefix VARCHAR,
_ingestion_id VARCHAR
)
WITH (
format = 'PARQUET',
location = 's3a://demo/bronze/nyc_fhvhv_iceberg/',
partitioning = ARRAY['day(pickup_datetime)']
);
4️⃣ Step 3 — Insert Landing Data into Iceberg
INSERT INTO iceberg.bronze.fhvhv_tripdata_raw
SELECT
hvfhs_license_num,
dispatching_base_num,
originating_base_num,
request_datetime,
on_scene_datetime,
pickup_datetime,
dropoff_datetime,
PULocationID,
DOLocationID,
trip_miles,
trip_time,
base_passenger_fare,
tolls,
bcf,
sales_tax,
congestion_surcharge,
airport_fee,
tips,
driver_pay,
cbd_congestion_fee,
shared_request_flag,
shared_match_flag,
access_a_ride_flag,
wav_request_flag,
wav_match_flag,
current_timestamp,
's3a://demo/landing/nyc_taxi/2026/02/26/',
to_hex(md5(cast(current_timestamp as varchar) || cast(random() as varchar)))
FROM hive.landing.fhvhv_tripdata_202601_landing;
What happens in MinIO?
New structure appears:
demo/bronze/nyc_fhvhv_iceberg/
├── data/
│ ├── *.parquet
└── metadata/
├── v1.metadata.json
├── snapshot-*.avro
└── manifest files
This is a fully managed Iceberg table.
5️⃣ Step 4 — Create Delta Bronze Table
Now we do the same promotion — but into Delta format.
CREATE SCHEMA IF NOT EXISTS delta.bronze
WITH (location = 's3a://demo/bronze/_schemas/bronze/');
DROP TABLE IF EXISTS delta.bronze.fhvhv_tripdata_raw;
CREATE TABLE delta.bronze.fhvhv_tripdata_raw (
hvfhs_license_num VARCHAR,
dispatching_base_num VARCHAR,
originating_base_num VARCHAR,
request_datetime TIMESTAMP(6),
on_scene_datetime TIMESTAMP(6),
pickup_datetime TIMESTAMP(6),
dropoff_datetime TIMESTAMP(6),
PULocationID INTEGER,
DOLocationID INTEGER,
trip_miles DOUBLE,
trip_time BIGINT,
base_passenger_fare DOUBLE,
tolls DOUBLE,
bcf DOUBLE,
sales_tax DOUBLE,
congestion_surcharge DOUBLE,
airport_fee DOUBLE,
tips DOUBLE,
driver_pay DOUBLE,
cbd_congestion_fee DOUBLE,
shared_request_flag VARCHAR,
shared_match_flag VARCHAR,
access_a_ride_flag VARCHAR,
wav_request_flag VARCHAR,
wav_match_flag VARCHAR,
_ingest_timestamp TIMESTAMP(6),
_source_prefix VARCHAR,
_ingestion_id VARCHAR
)
WITH (
location = 's3a://demo/bronze/nyc_fhvhv_delta/'
);
6️⃣ Step 5 — Insert Landing Data into Delta
INSERT INTO delta.bronze.fhvhv_tripdata_raw
SELECT
hvfhs_license_num,
dispatching_base_num,
originating_base_num,
request_datetime,
on_scene_datetime,
pickup_datetime,
dropoff_datetime,
PULocationID,
DOLocationID,
trip_miles,
trip_time,
base_passenger_fare,
tolls,
bcf,
sales_tax,
congestion_surcharge,
airport_fee,
tips,
driver_pay,
cbd_congestion_fee,
shared_request_flag,
shared_match_flag,
access_a_ride_flag,
wav_request_flag,
wav_match_flag,
current_timestamp,
's3a://demo/landing/nyc_taxi/2026/02/26/',
to_hex(md5(cast(current_timestamp as varchar) || cast(random() as varchar)))
FROM hive.landing.fhvhv_tripdata_202601_landing;
What happens in MinIO?
demo/bronze/nyc_fhvhv_delta/
├── _delta_log/
│ ├── 00000000000000000000.json
│ ├── ...
└── part-*.parquet
This is now a fully managed Delta table.
7️⃣ Iceberg vs Delta — Physical Differences
| Iceberg | Delta |
|---|---|
| metadata/ directory | _delta_log/ directory |
| Snapshot-based metadata | JSON transaction log |
| Engine-agnostic design | Spark-native ecosystem |
| Strong multi-engine support | Strong Spark/Databricks integration |
8️⃣ Final Result
You now have:
Raw immutable files
demo/landing/nyc_taxi/2026/02/26/*.parquet
Managed Iceberg Bronze
demo/bronze/nyc_fhvhv_iceberg/
Managed Delta Bronze
demo/bronze/nyc_fhvhv_delta/
You have successfully implemented a Lakehouse promotion pipeline on MinIO.
Why This Matters
This workflow demonstrates:
- Separation of landing vs managed layers
- Catalog-aware design (Hive vs Iceberg vs Delta)
- Object storage physical layout understanding
- Table-format-level governance
This is not “just writing SQL”.
This is platform engineering.